
Easily Extract Data from SQL Server for Fast & Visual Analytics with OmniSci
Download HEAVY.AI Free, a full-featured version available for use at no cost.
GET FREE LICENSEIn preparation for releasing version 5.0, OmniSci continues to become more feature-rich as customers and community members help us understand how GPUs transform their analytics and data science workloads. However, in the same way you wouldn’t drive a racecar to the supermarket, OmniSci will never be the right tool for every data use case. Rather, we’re striving to be the leading visual analytics platform for the use cases we’re targeting and complementary to other best-of-breed tools in the enterprise. To that end, OmniSci provides industry-standard connection interfaces (ODBC, JDBC), several open-source client packages (JavaScript, Python, Julia) and some OmniSci-specific utilities like SQLImporter and StreamImporter to help users bridge their legacy systems and OmniSci.
In this post, I’ll demonstrate a common scenario in mature enterprises: having data on several different systems and needing to transfer data to a common platform for analysis. Specifically, I’ll show how to export data from Microsoft SQL Server to OmniSci, so that customer account data from SQL Server can be merged with the customer transactional data on OmniSci and then visualized using OmniSci Immerse.
System-of-Record vs. Analytics Platform
In my career, I’ve worked at several Fortune 100 companies, both as an employee and as an external consultant. The industries have varied, but one common feature of the technology stacks at these companies has been that one database that both 1) holds all of the business-critical data and 2) no one is allowed to actually use! The database could be any of the major platforms such as Teradata, Oracle or SQL Server, but no matter what, no ad-hoc queries were allowed to be run during business hours by anyone other than a select few DBAs.
What this type of roadblock inevitably leads to is a series of data export jobs to a data lake or other analytics system where analysts had more freedom for exploration: this is where OmniSci thrives! Being built from the ground up to be an agile, interactive data exploration platform for driving insights, OmniSci allows users to run queries faster than system-of-record/row-oriented databases, as well as provides graphical capabilities that just aren’t possible with large CPU-only databases.
Transferring Customer Account Table to OmniSci
To demonstrate using OmniSci as the common platform between multiple data systems, let’s assume we have a monthly subscription-based service where the customer account data is stored in SQL Server. The customer account table might have the following schema:

To make the example more interesting, I’ve given the address_geom column a type of GEOGRAPHY both SQL Server and OmniSci support OGC-compliant geospatial data types, but because the data are represented slightly differently in the two systems, we’ll have to account for this before transferring the data.
Using SQLImporter: SQL Server to OmniSci
To transfer data between SQL Server and OmniSci, there are several options. The lowest common denominator between any two databases is dumping to CSV, but that loses all the benefits of knowing the data types in advance. Additionally, we could write some Python code or similar, but that requires more development than just simply copying a table from one database to another. My recommendation in terms of ease-of-use is to use SQLImporter, a Java utility provided with each OmniSciDB install. SQLImporter uses JDBC to read from the source database and the OmniSci JDBC driver to insert data to the database.
Find Java Runtime Environment Version
In this example, we’ll need the Microsoft SQL Server JDBC Driver; to ensure you get the correct version for your database, you need to check your version of Java:
The number after the '1.' in the Java version is the required Java Runtime Environment version. In this case, because the Java version is 1.8.x_xxx we need the jre8 version of the SQL Server JDBC driver: mssql-jdbc-7.4.1.jre8.jar
Copying an Entire Table to OmniSci
To copy an entire table from SQL Server to OmniSci, you can do the following:
The java arguments declare where the database jar files are located, the credentials for each database and then a select-all statement from the table: "select * from dbo.customers". If the table specified with the `-t` argument doesn’t exist on OmniSci, the table will be created; if the table does exist, then the column names and data types of the SQL Server table and the target OmniSci table must match.
If you are doing a one-time transfer of a table, the code snippet above with automatic table creation is usually sufficient. However, for repeated workflows such as a daily export, it’s recommended that you both specify the exact query from your target database as well as pre-create your table in OmniSci for maximum stability of the data pipeline, as well as optimizing the column type definitions in OmniSci.
Copying Selected Rows/Columns to OmniSci
For our specific SQL Server example, let’s assume that we have 140 million rows in the 'customers' table. While 140 million records isn’t that large by modern database standards, if we’re only interested in a specific customer segment, then we might choose to add a WHERE clause to our table statement. Or, maybe we don’t want to copy Personally Identifiable Information (PII) into an analytics database. Regardless of the specific transformation, the important thing here is that SQLImporter will allow you to specify the exact query you want to run in SQL Server to copy over to OmniSci, which might look something like this:
In this export statement, we choose 'customerid' (our primary/join key to other tables), the 'service_address' and the building footprint as 'address_geom'. To ensure that 'address_geom' loads properly into OmniSci, we need to transform from the SQL Server storage format of Well-Known Binary (WKB) to Well-known Text (WKT) which is what OmniSci accepts as part of the import path. Since this example is using SQL Server as the data source, we convert the 'address_geom' column using T-SQL, the SQL dialect that SQL Server uses: address_geom.STAsText ()
High-Performance Visual Geospatial Analytics Using OmniSci Immerse
Once the customers table with location data has been transferred into OmniSci, we can merge our transaction-level data to create a dashboard like our Crowdsourced Mobile Network Quality demo:
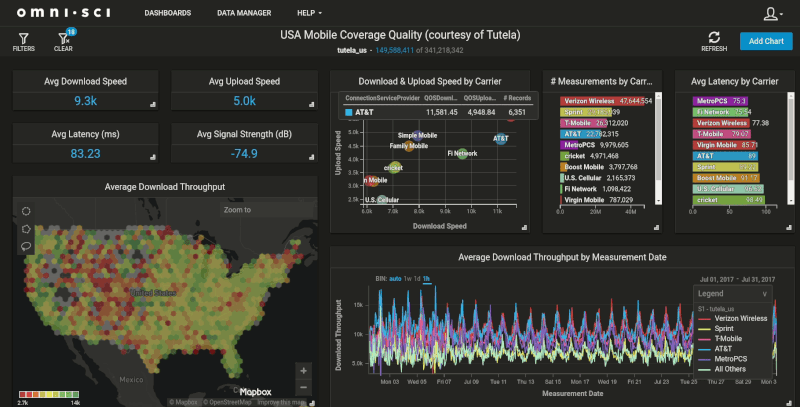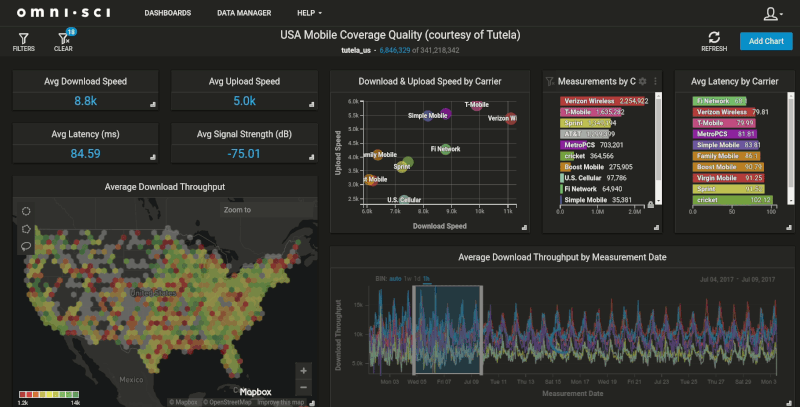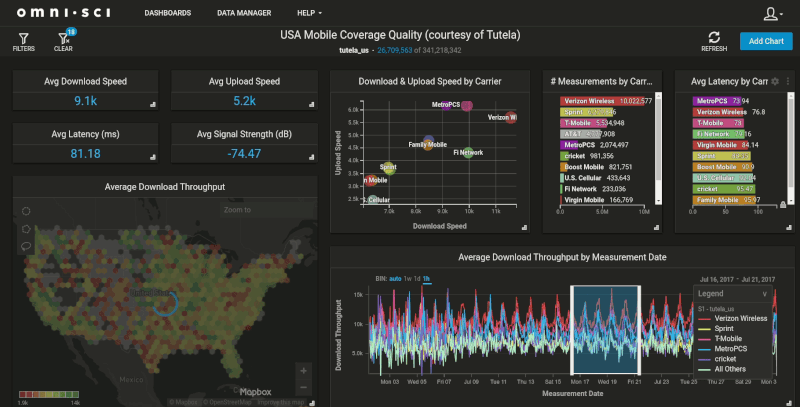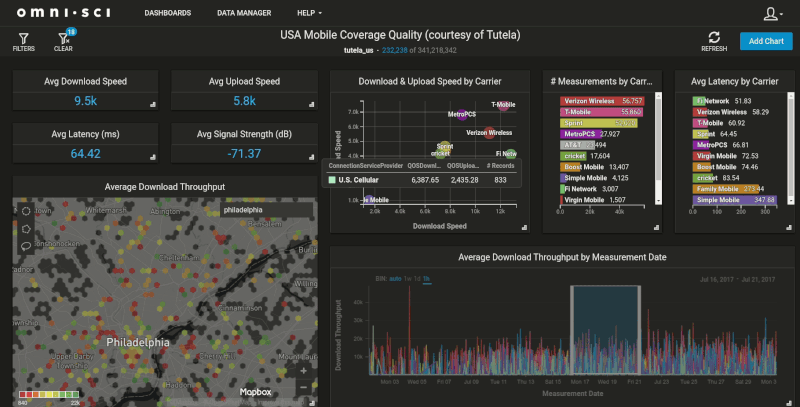
With the massive memory bandwidth and core density provided by GPUs, OmniSci Immerse makes this customer data easy to join and extremely fast to query. How fast? In testing for this post, I found that simple 'STDistance()' queries that took 4-5 minutes on SQL Server were executing at 300-500 milliseconds on OmniSci. We also acutely see the speed improvement in the rendering of the geospatial data, which is another advantage OmniSci has running on GPUs. The database passes the results of the query back to the rendering engine running on the same GPU, which creates the geospatial visualization. This means we’re just sending a small PNG image down to the client, instead of expecting the client to handle the rendering of these large, complex datasets.
Next Steps
Now that you’ve seen how to get the performance of OmniSci with your existing SQL Server data, why not give it a try? If you want to run on your local machine or server, download the 30-day trial of OmniSci Enterprise Edition. If you want to run in one of the public clouds, the OmniSci package is already in the marketplace for Azure, AWS, and Google Cloud, just click through and spin up your instance. Finally, we also offer OmniSci as a managed service, via our OmniSci Cloud.
From October 21 - 23 we’re also hosting Converge in Mountain View, California, our first conference for accelerated analytics and data science. At the event, you’ll see OmniSci in action and meet the team behind the platform. If you’re interested in joining, use the code “Community50” and get 50% off the registration price.



