
Creating the OmniSci F1 Demo: Real-Time Data Ingestion With StreamSets
Download HEAVY.AI Free, a full-featured version available for use at no cost.
GET FREE LICENSEIt’s been about six weeks since the NVIDIA GTC 2019 conference in San Jose, which was an overwhelming success for OmniSci due to being featured in the keynote by NVIDIA CEO Jensen Huang as well as having an F1 driving simulator in our booth. Since Jensen is too busy to tell the world each week how amazing OmniSci’s visualization and data science capabilities are, the OmniSci Community team decided to do the next best thing: take the F1 simulator on the road to local meetups!
Each time we demonstrate the real-time streaming data capabilities of OmniSci via the F1 demo, we usually get one of two reactions: “You hacked a video game?” and “Hmm...better drive a lap to make sure this is real!” Since it’s difficult to explain the engineering behind the F1 demo over the roar of the engines and laughter as people drive questionably, here’s an outline of how to stream data into OmniSci in real-time using StreamSets. If you’re interested in the code details to replicate the demo yourselves, we’ve open-sourced the entire F1 demo on GitHub.
Vehicle Telematics: a VAST problem
The goal of the F1 demo is to demonstrate a set of challenges that we refer to internally at OmniSci as VAST:
- Volume: how to manage high data Volume
- Agility: how to maintain the ability to interact with the data in an Agile manner
- Spatio-Temporal: data (often) has a Spatio-Temporal component which considers both time and 3D space
You may have seen our blog post about VAST and vehicle telematics prior to NVIDIA GTC so I won’t recap the full post here, but our F1 demo was designed to demonstrate how OmniSci can ingest a stream of data AND allow that data to be analyzed interactively in real-time. This powerful capability is made possible by the massive bandwidth and computing power provided by GPUs and harnessed by OmniSci.
StreamSets: How to Build Amazing Data Pipelines (without serious DevOps chops!)
To accomplish the data engineering portion of the F1 demo, we used StreamSets, an amazing open-source data pipeline tool that I cannot say enough good things about. StreamSets allows anyone to connect a data Origin and Destination without necessarily having to write code.
The data pipeline for our F1 demo is comprised of three parts outlined below in a step-by-step guide. Additionally, I’ll discuss the engineering choices and tradeoffs we made while structuring the data pipeline.
- Listen on UDP socket, Write to Apache Kafka Producer
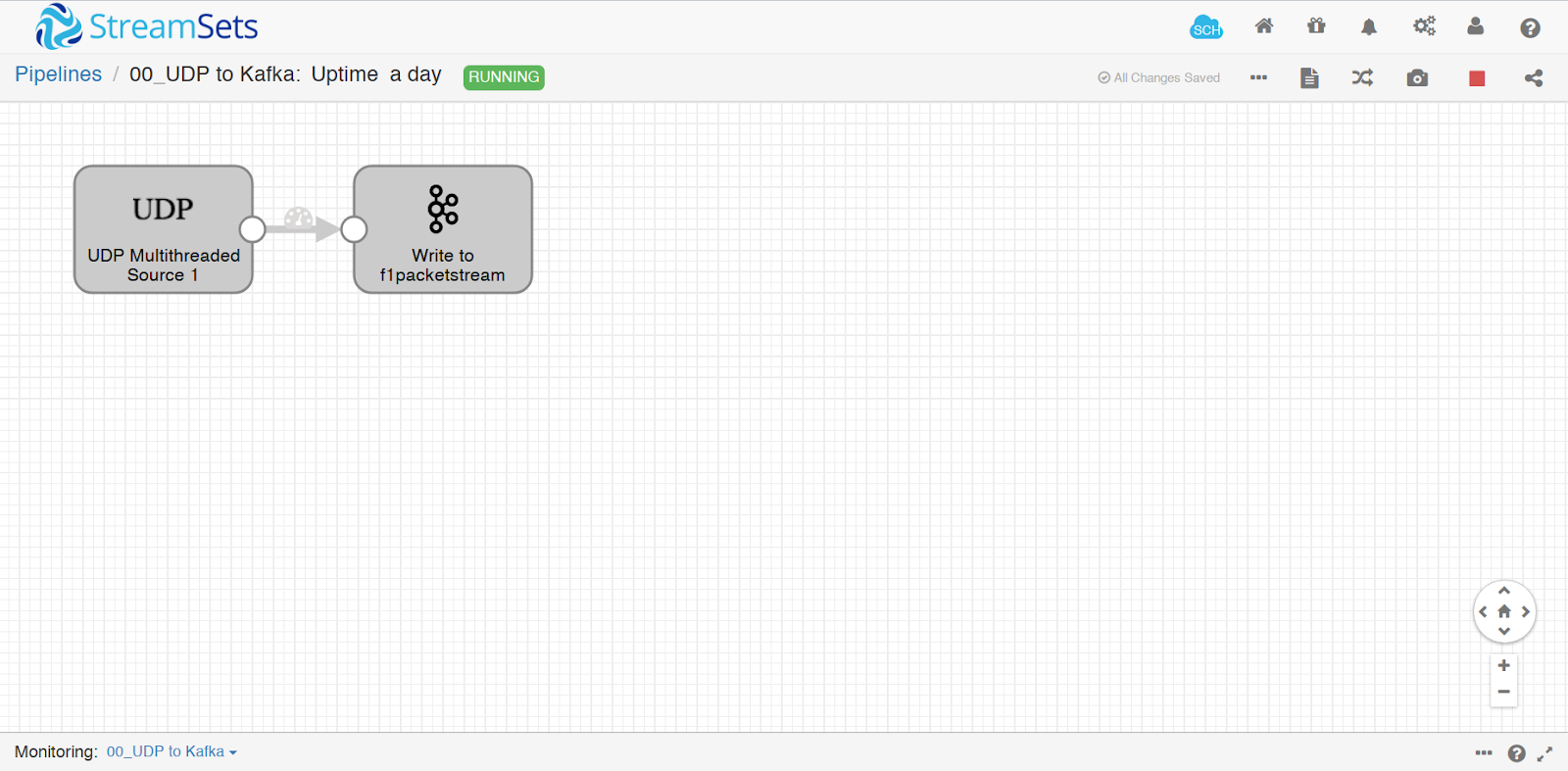
- The first part of the data pipeline is getting the data out of the F1 2018 game from Codemasters. Codemasters provides telemetry functionality within the game settings, so that users can add various hardware peripherals or dashboard apps by choosing an IP address/port to receive a stream of UDP packets. The data stream has settings of 10hz/30hz/60hz (hz: units per second). We chose 60hz to make sure we had the fastest possible stream and richest data set to work with.
- Admittingly, having this first part of the data pipeline go from the UDP socket directly to Apache Kafka was a happy accident in the design, but ultimately ended up being a sound decision. When starting out this project, I didn’t know that it would work. The UDP packet is in a packed struct format with the spec provided by Codemasters, but there was still an open question remaining: how to parse these bits into usable data?
- My first step was just to record my driving data by writing it to Apache Kafka, and then “figuring out what to do later.” By making this design decision though, it allowed us to scale the number of threads for the UDP listener independently from the rest of the data pipeline. Additionally, decoupling the data collection from the data parsing means that we can change the data pipeline transformation steps and re-run the pipeline, or perform other administrative tasks such as take the OmniSci database down for maintenance without losing incoming packet data.
- Parse Data from Apache Kafka Consumer, Write Back to Kafka
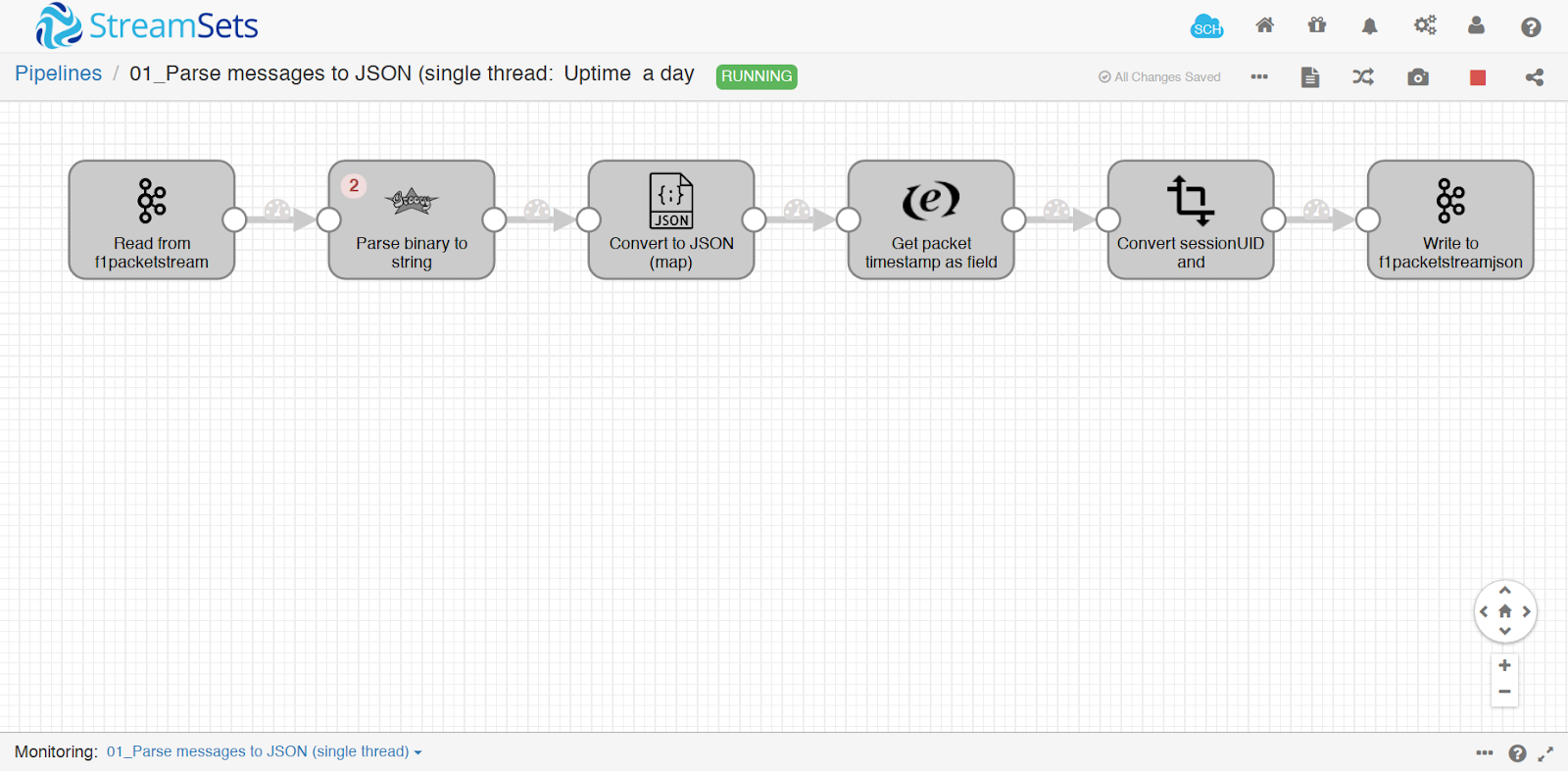
- Data was now reliably flowing from the UDP socket into a Kafka topic. Now, I needed to solve the problem of getting the data into a usable format. Again, I was still winging it at this stage of the prototype. Since JSON is often the least common denominator between any set of data tools, I parsed the data to JSON and then wrote that data to Kafka.
- For me, the most interesting part of this stage of the pipeline is the second step, which uses the StreamSets Groovy Evaluator. First, I evaluated using Python (outside of StreamSets) to parse the F1 UDP packet. While this worked, I was concerned about maintaining two separate pipelines (StreamSets and Python). I was lucky enough to find an open-source Java project to parse the UDP packet. However, in testing this library using the StreamSets Jython Evaluator, I found a certain feature used in the Java parsing library wasn’t thread-safe in Jython. This caused a complete pipeline shutdown within a matter of seconds of starting the data pipeline.
- Eventually, after some panicked messages on the StreamSets Slack (special thanks to Pat Patterson for being so patient with me!), I figured out how to call the Java library using Groovy; not being a Java person, it took longer than it should’ve, but the Groovy Evaluator is thread-safe and considerably faster than Jython.
- After the Groovy Evaluator step, the data goes through a handful of data cleansing steps (none of which are worth discussing), then the data is written out to a second Kafka topic. This time, the data is holding the parsed JSON.
- Consume JSON from Kafka, Split into Workflows, Insert to OmniSci Using JDBC
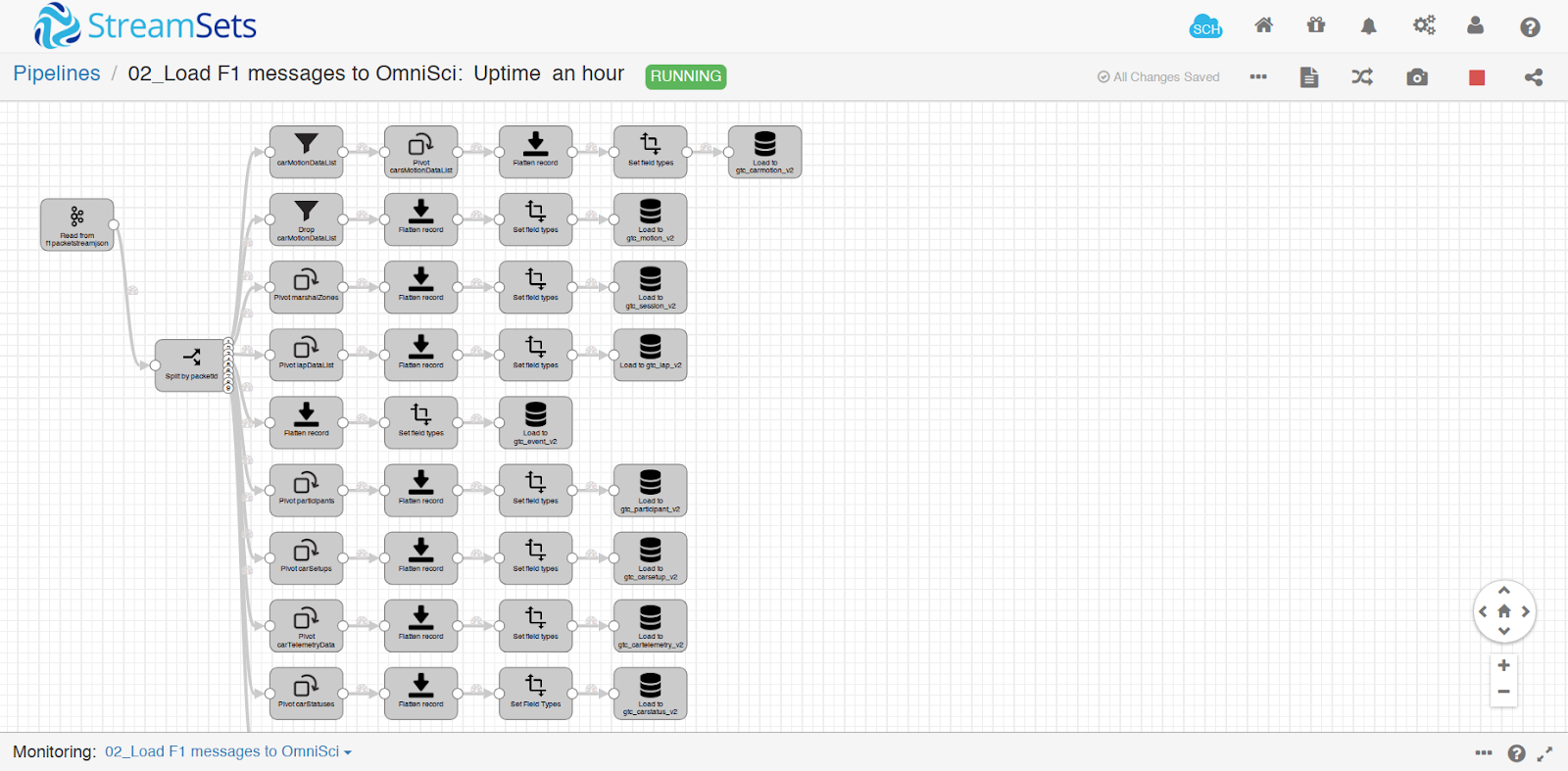
- The final steps of the F1 demo data pipeline are to consume the JSON from the JSON Kafka topic, read the ‘packetId’ value from the JSON to understand which type of packet it is, then pass it into a unique workflow based on the type of data. The F1 2018 UDP specification has eight data types, each with a different structure. Some of the packet types also have data arrays in them, which means they need to be pivoted into individual records. Suffice to say, this is the most intense part of the data pipeline and also the most rewarding to watch.
- The Kafka Consumer gives you the option of setting the number of threads to increase parallelism. When originally creating the Kafka topics, I chose a default of eight partitions, because that’s what I saw in an example. For this portion of the F1 demo data pipeline, I used eight threads to read from the eight partitions in batches of 1000 messages. The data flows through the individual parsing steps, eventually getting to the end node which inserts the data into OmniSci via Java Database Connectivity (JDBC).
- So, just how much data volume are we talking about here?
- When the game is running, it creates approximately 14 MB of data per minute in the binary UDP form. When unpacked, the number of records increases approximately 20x. When someone is driving a lap and the data pipeline is in its steady state, the pipeline inserts approximately 5,000 - 6,000 records per second into eight different OmniSci tables.
Is This the Best Way to Insert a Real-Time Stream into OmniSci?
As I built this demo, I learned a lot about data engineering and the capabilities of OmniSci.
First, knowing what you are doing is very important! As a growing startup, I worked on the F1 demo almost completely on my own; this was a stressful mistake, but likely the only way this project could’ve gotten done in time. Without the support of many important open-source tools and forums, mostly StreamSets, this demo would’ve never seen the light of day. I also learned (as a mostly Python and Julia programmer) that threaded programming and working with JVMs are their own specialties, and unfortunately, not one I currently possess. This lead to some really painful debugging, which I hope to not repeat any time soon.
Secondly, in looking at this blog post and published code repository, it certainly raises the question “is this the optimal way of inserting a real-time stream into OmniSci?” Certainly, there are parts that wouldn’t be considered high-performance. The data is taken from a binary stream and converted into JSON, losing all the value of a strongly-typed, compiled language like Java. And using JDBC is generally not considered a “fast” method, at least not in the sense of in-memory approaches such as Apache Arrow and shared memory transfer. But this F1 demo data pipeline is maintainable, functions as expected and it writes data fast enough for our use case.
In close, the takeaway from this blog post is not necessarily that you should build your next data pipeline this way, but that you could. In the case of the F1 demo, this pipeline ingests data fast enough where a user driving on the F1 track can also watch their telemetry data streaming by on a visual dashboard. Like all engineering projects, trade-offs were made, and ultimately this pipeline shows a representative example of how a real-time data pipeline can be built using only open-source tooling including OmniSci.
Next Steps: Building the F1 Demo Dashboard with Dash by Plotly
In my next blog post, I’ll cover the second half of the F1 demo, which is a dashboard built using dash by plotly to plot track position, the leaderboard and telemetry metrics like speed, engine rpm, gear, etc., all in real-time. Until then, the GitHub repo for the OmniSci F1 demo has all the code you need to recreate the demo and we’ve even published all of the data to an S3 bucket so that you can play around with the data in OmniSci.
We’d love to see how you would analyze this vehicle telematics data, using OmniSci Core or OmniSci Cloud. If you come up with an interesting visualization or use our Python client pymapd to do an interesting analysis, please stop over to our Community Forum and share your results. We’ve only scratched the surface of what’s possible from this dataset, so we welcome any and all feedback on this post, the data or any other part of the F1 racing experience.
Until then, happy racing and analyzing using OmniSci! Vroom!



