5 Tips for Big Geospatial Analytics with MapD
Download HEAVY.AI Free, a full-featured version available for use at no cost.
GET FREE LICENSEFeatures
- Auto-convert Longitude/Latitude data to geometric POINTS
- Configure MapD to enable loop-joins
- Use ST_Contains to find POINTS within MULTIPOLYGON
- Use ST_Distance to find distance in meters
- Use ogr2ogr to convert MULTILINESTRING to LINESTRING
1. Auto-convert Longitude/Latitude data to geometric POINTS
In MapD 4.0, we added native support for several geospatial data types, including POINT. If you have longitude and latitude data in separate columns, you can import it as a single geometric POINT column by specifying it in the definition of the table. In addition to rendering the geometric points in an Immerse Pointmap, having the single column lets you use the geospatial functions ST_Distance and ST_Contains. Having a geometric point column opens up many possibilities to combine location information with other geospatial datasets (POINT, POLYGON & LINESTRING) to gain additional insights into your data.
Let’s create a CSV file with a few records representative of a website traffic information:
Here’s how we would create a table with separate columns for longitude and latitude:
Here’s how we would create a table with separate columns for longitude and latitude:
mapdql> CREATE TABLE website_data (accessDateTime TIMESTAMP, longitude FLOAT, latitude FLOAT, landingPagePath TEXT ENCODING DICT(8), networkLocation TEXT ENCODING DICT(8), sessionDuration BIGINT);
mapdql> copy website_data from '/mapd-storage/website_data.csv';
Result
Loaded: 6 recs, Rejected: 0 recs in 0.146000 secs
Now we’ll create a table with a single POINT column which includes the information from the two columns as longitude (x) and latitude (y). By default when the table importer finds scalar values in the CSV row for a POINT column, it consumes two consecutive columns as longitude and latitude. If the order of the coordinates in the CSV file is opposite (latitude, longitude), then load the data using the WITH option lonlat='false'.
Create table with a geometric POINT column with the SRID (Spatial Reference Identifier) defined:
You can also confirm the creation of the POINT column by listing the table definition. You will see that the POINT column is stored as geometry in geodetic coordinate system EPSG 4326. By default, geo data is stored compressed by 50% in a 4 byte INTEGER instead of 8 bytes BIGINT. This compression reduces the memory footprint and speeds query execution, at the cost of lower resolution (about 4 inches at the equator). If you want full 64-bit accuracy then disable compression by specifying ENCODING as NONE.
mapdql> \d website_data_with_geo
CREATE TABLE website_data_with_geo (
accessDateTime TIMESTAMP(0),
mapd_geo GEOMETRY(POINT, 4326) ENCODING COMPRESSED(32),
landingPagePath TEXT ENCODING DICT(8),
networkLocation TEXT ENCODING DICT(8),
sessionDuration BIGINT)
NOTE: If the SRID is not specified then performing geospatial functions using the POINT data will lead to erroneous results. You can query the SRID of the geodata column using the ST_SRID function:
mapdql>select ST_SRID(mapd_geo) from website_data_with_geo limit 2;
EXPR$0
4326
4326
2. Configure MapD to enable loop-joins
The default configuration setting for MapD server disables loop joins, as they are computationally expensive. This setting nudges the user to specify an equality join condition in the query to get the best performance. However, using a geospatial function will result in non-equijoins, which requires enabling the loop join in MapD server. Additionally, when using ST_Contains, you will get the best performance if the table with polygons is on the right of the join, i.e. `SELECT COUNT(*) FROM point_table, polygon_table WHERE ST_Contains (polygon_table.polygon_col, point_table.point_col)` so all points would be iterated over for each polygon and not the other way around. By default, MapD reorders tables for joins such that the larger table gets pushed to the left. This may get in the way of setting the preferred order described above. To ensure that your poly table stays on the right, explicitly disable table reordering using the from-table-reordering flag in the mapd_server config.
The reasoning behind requiring the larger geo type on the left side is that polygons can be of widely varying size, which can cause high skew when computing the join. To minimize computational divergence across cores, the polygon table should always be the inner table, so each polygon is processed at the same time across all cores.
Add the following lines in the mapd.conf file and restart the MapD server:
allow-loop-joins = true
from-table-reordering = false
3. Use ST_Contains to find POINTS within MULTIPOLYGON
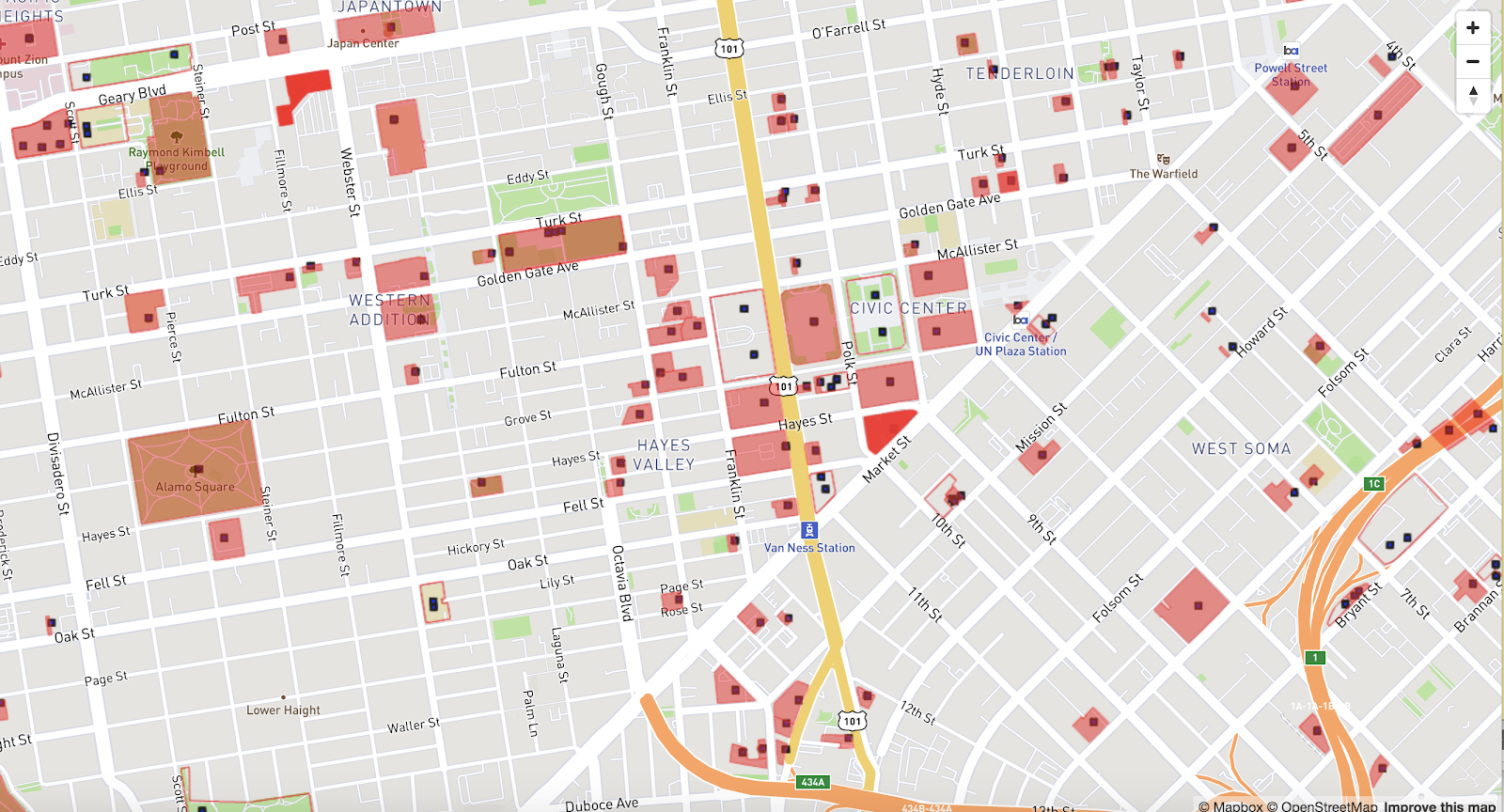
The function ST_Contains(geom1, geom2) returns true if the first geometry object contains the second object. Let us join the San Francisco city parcel dataset (MULTI-POLYGONS) with the city facilities dataset (POINT) and find all the city parcels that contain a facility maintained by the city. When using ST_Contains, make sure to use the native geometric datatype (EPSG 4326) for the most accurate results. Applying the Web Mercator (EPSG 900913) transform introduces some distortion and bending which may result in a point that is at the edge of the polygon to be pushed in or out of it.
Find the number of city facilities that are contained within the city parcels, using ST_Contains with native geometric EPSG 4326:
4. Use ST_Distance to find distance in meters
The SQL function ST_Distance returns the shortest planar distance between geometries. By default, geo data is stored as GEOMETRY, converted to Earth coordinates in lon/lat as Geodetic coordinate system EPSG 4326. So the SQL function ST_Distance will return the shortest planar distance in degrees. In order to get the distance in meters, you have to cast the geometries as geographies or project in Web Mercator.
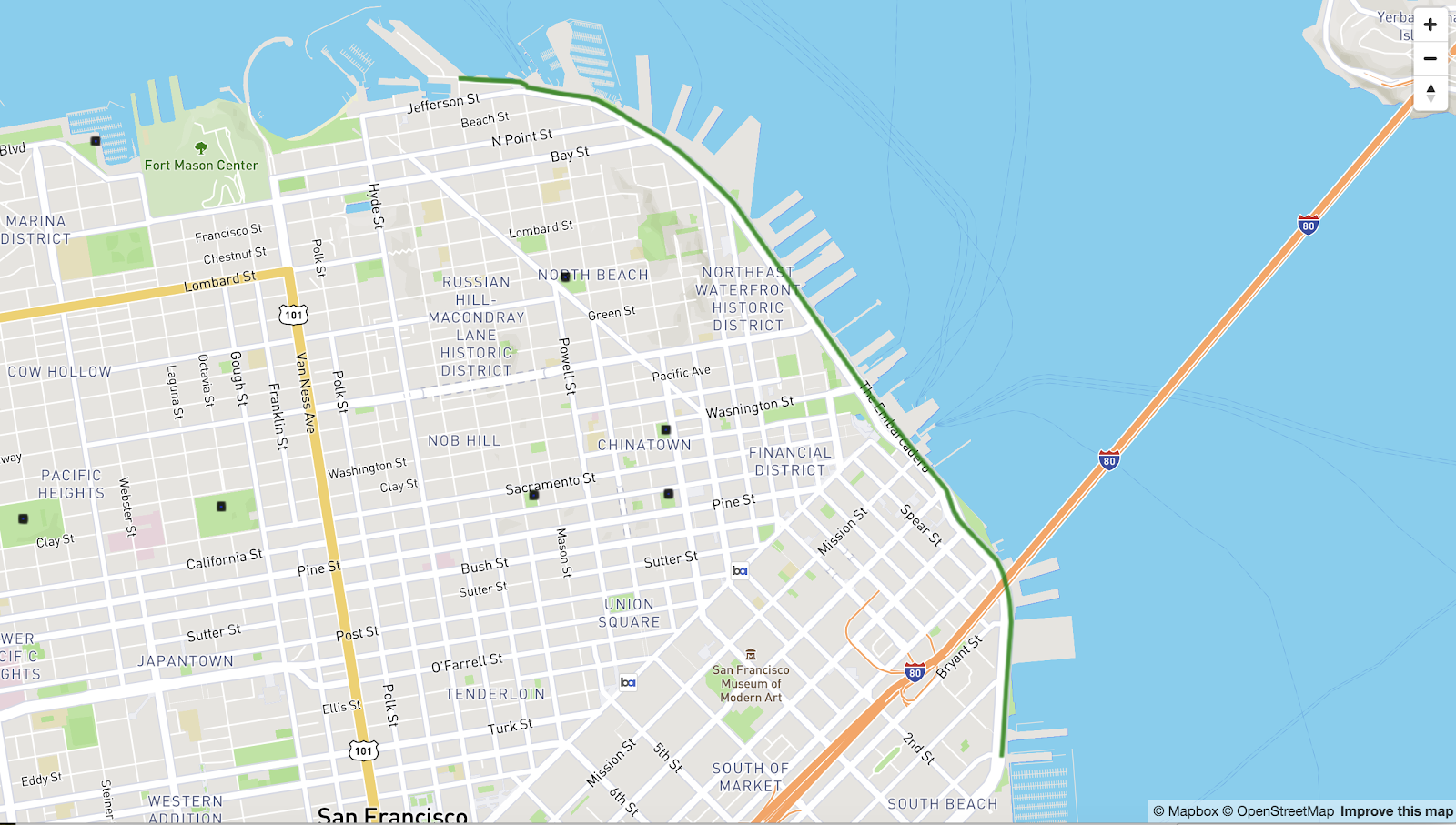
Let us see how we can use ST_Distance to solve a practical problem during my bike route along the Embarcadero in San Francisco. The map below shows the bike route in green and the black squares are the restrooms maintained by the city. You can find the link to the dataset and the MapD Vega code used for rendering under the mapd-vega-mapboxgl-geo project.
The data definition for the columns used in the query are:
Table: sf_bikeway
to_st TEXT ENCODING DICT(32),
from_st TEXT ENCODING DICT(32),
mapd_geo GEOMETRY(LINESTRING, 4326) ENCODING COMPRESSED(32))
Table: sf_facility
facility_n TEXT ENCODING DICT(32),
mapd_geo GEOMETRY(POINT, 4326) ENCODING COMPRESSED(32))
The ST_Distance function, using the geometric data type, returns distance in degrees:
ST_Distance using the geographic data type, returns the distance in meters:
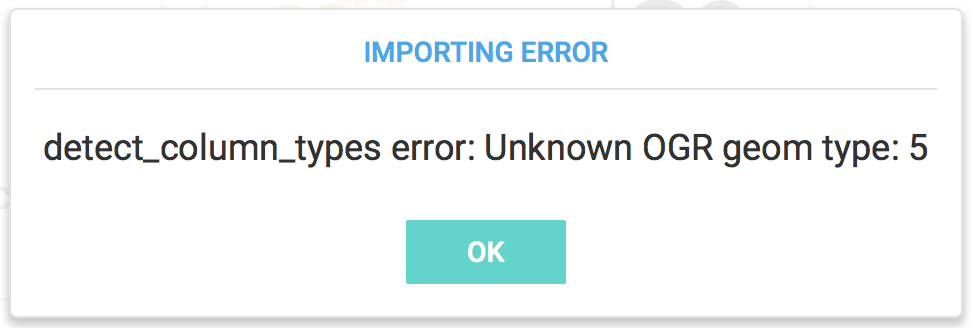
5. Use ogr2ogr to convert MULTILINESTRING to LINESTRING
MapD version 4.1 only supports LineString data and does not support importing MultiLineString data. If you try creating a table with MultiLineString data, you will see the following error:
Use the GDAL command line tool ogr2ogr to convert MultiLineString data to LineString. Here is a sample MultiLineString in GeoJSON format:
Use the ogrinfo tool to query the GeoJSON file and confirm the data type.
Use ogr2ogr to select the multiLineStrings and save them into a new GeoJSON file as a single part linestring.
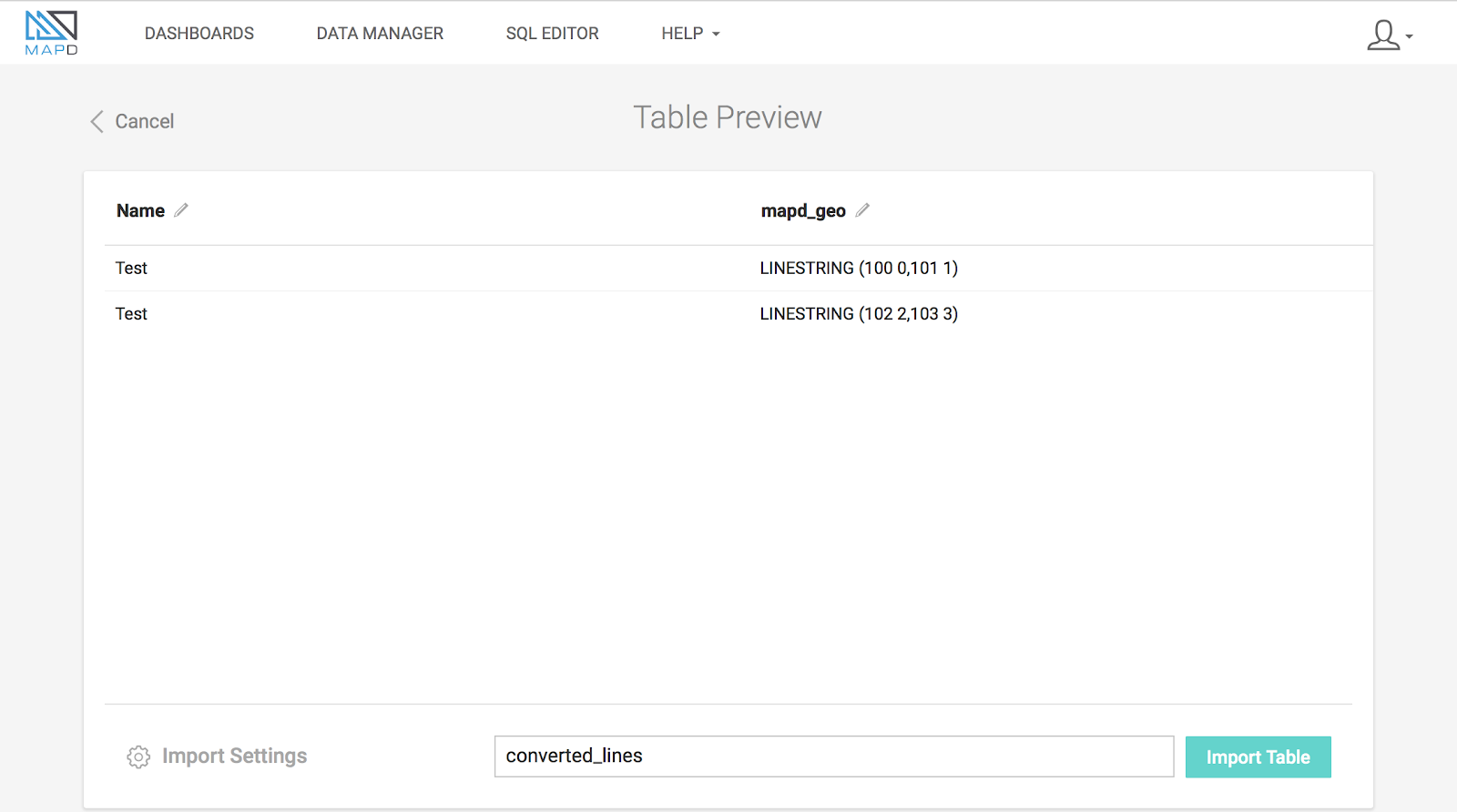
The JSON file converted_lines.json contains one lineString for each part of the multiLineString.
Using Immerse’s Import, you can successfully create the table with LINESTRING data column from the converted_lines.json file.